Easy Deep Insights
Introducing ParaStack
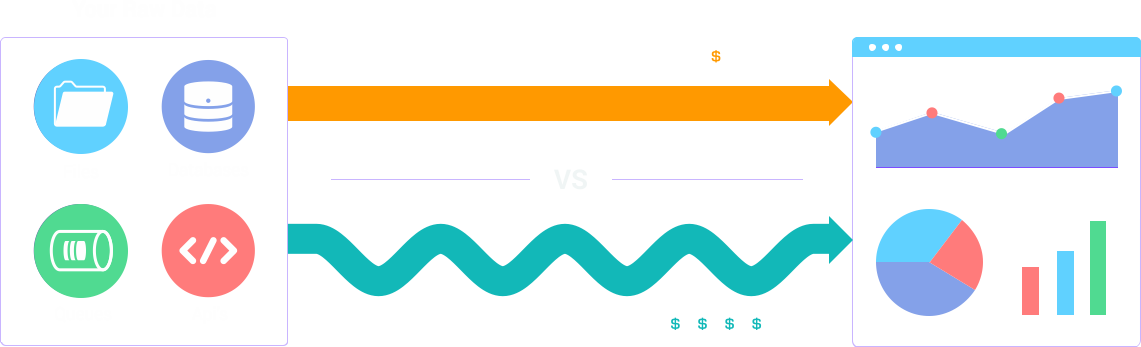
ParaStack is an end-to-end, turnkey healthcare analytics platform, that empowers you to analyze your scattered, raw, dirty data sources into trustable, actionable insights.
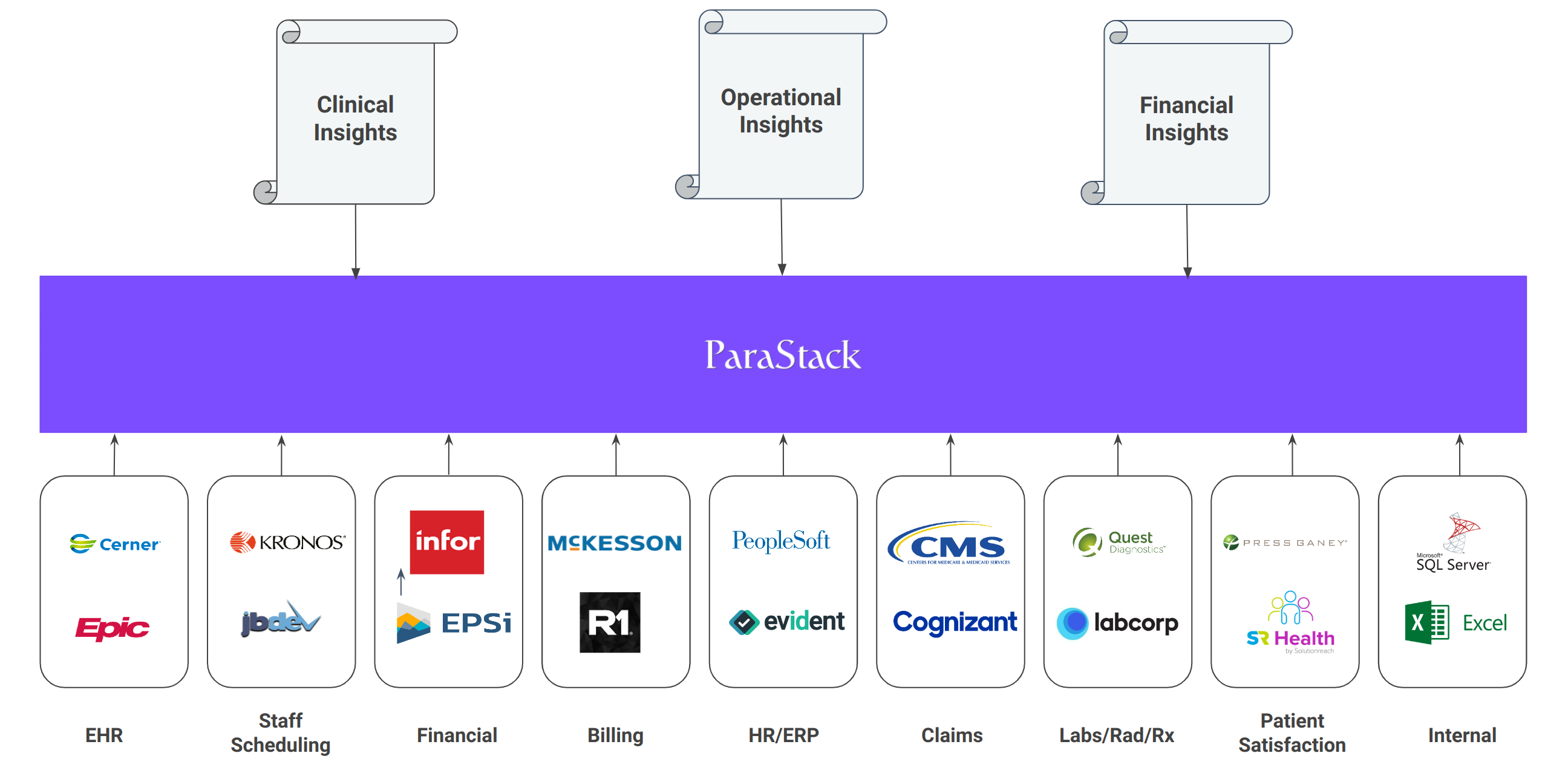
ParaStack is an end-to-end, turnkey healthcare analytics platform, that empowers you to analyze your scattered, raw, dirty data sources into trustable, actionable insights.
Why ParaStack?

Any Data Source

Any Data Size
Any Data Type

Any Analytics
Take a quick product tour
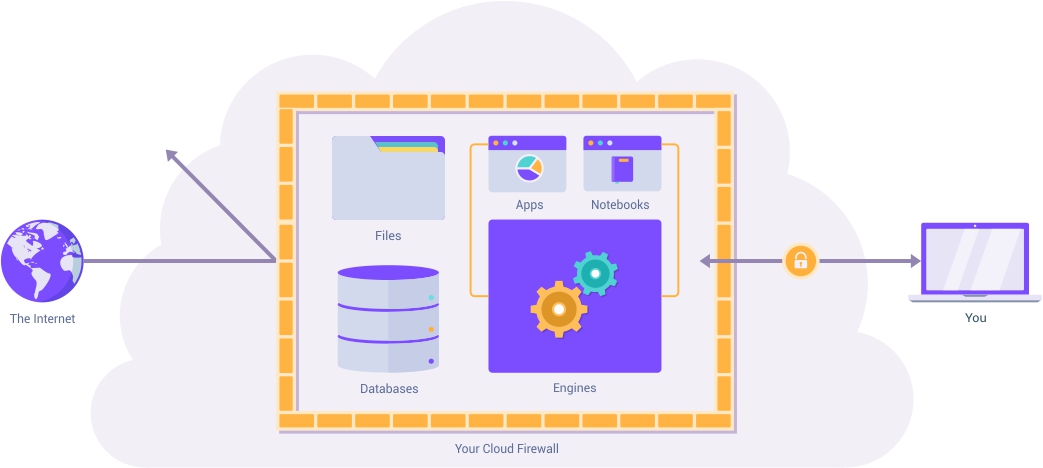
Your Data Never Leaves Your Organization
ParaStack Data Crunchers comes to life inside your own IT environment within your own firewalls where your data was initially generated. That way, you never have to move data to another third party service.
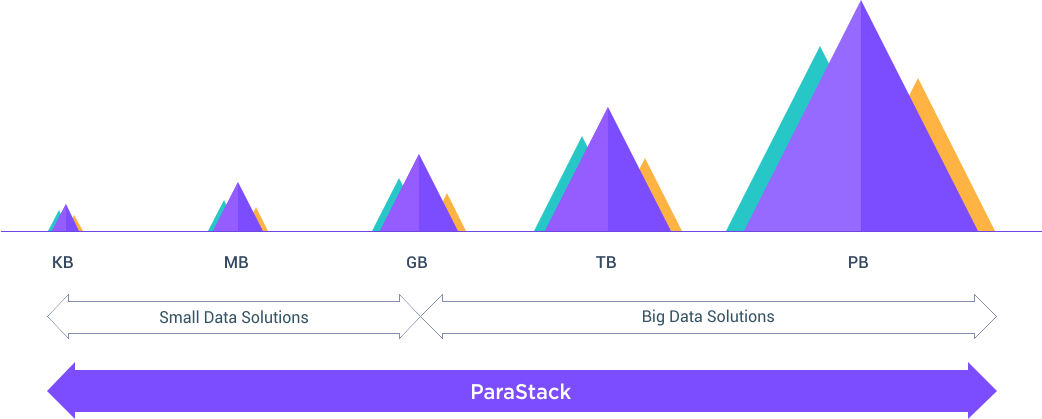
One Solution For Your Small And Big Data
Big problems start small, and ParaStack is built to offer you a complete solution as your scaling needs and requirements change through your project’s lifecycle.
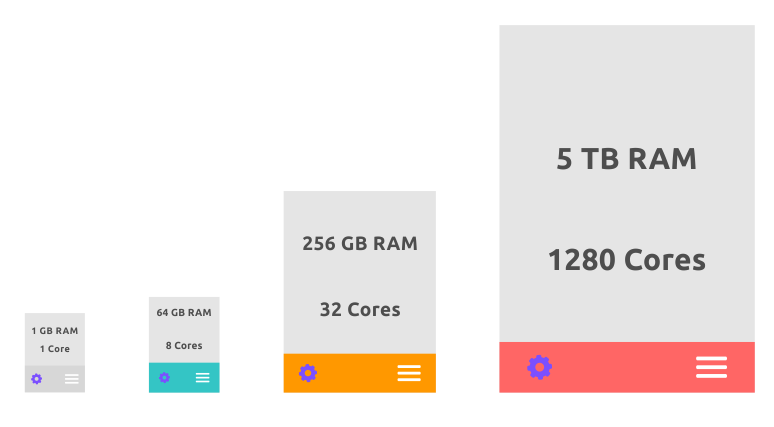
ParaStack Scale From Tiny To Massive
Automatically Scale your ParaStack Data Crunchers to the desired size with a few clicks and no human intervention and leave the heavy lifting to us.
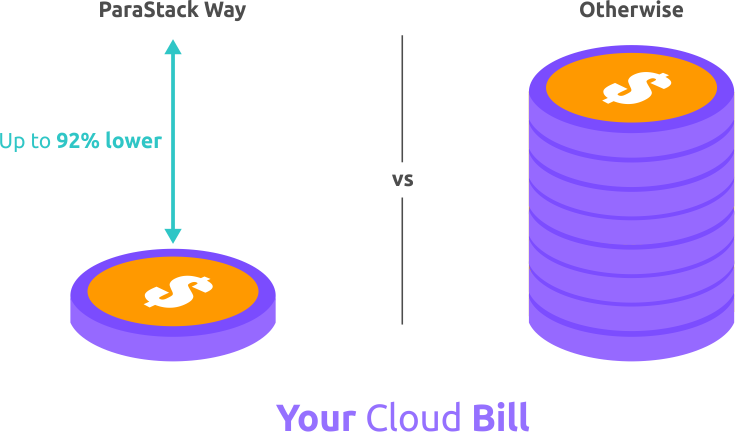
Your Cost Couldn’t Get Any Lower
You couldn’t possibly lower your data processing operational costs TCO any further.