Secure
ParaSpark gives you maximum security and privacy by deploying straight into your own cloud account, inside your own private VPC network with role-based access control

Full Control Over Data Access Using Roles
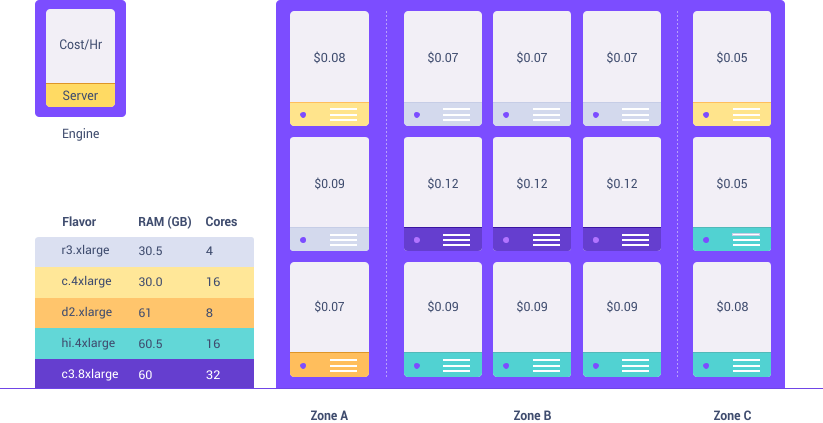
ParaStack engines integrate deeply with your Amazon AIM roles and enables you to enforce your desired data access configuration down to the file and table levels. You can add and remove your access rules on the fly and ensure they are enforced immediately.


Isolated Network
Your ParaStack engines are provisioned inside an automatically created private network within your own cloud to add an extra layer of security. This also means that you can easily connect your on-prem infrastructure and ParaStack engines, using an encrypted IPsec VPN.
At-Rest Data Encryption
Integrating with Amazon Key Management Service (KMS), you can encrypt all your data at rest with your keys secured using Hardware Security Modules (HSMs).


Transitioning Data Encryption
Your authenticated connection from your browser to your engines are fully encrypted with industry standard SSL/TLS.
Automatic Data Sources Authentication
ParaStack engines automatically authenticates to your cloud resources using AWS Instance role and access level.